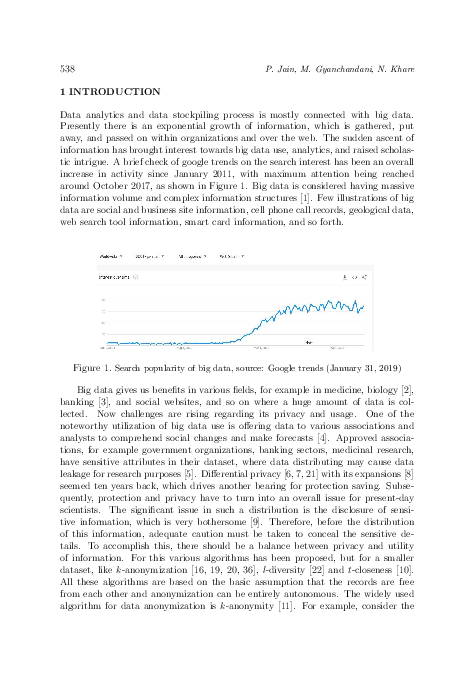
Improved k-Anonymize and l-Diverse Approach for Privacy Preserving Big Data Publishing Using MPSEC Dataset
keywords: Big data, privacy, k-anonymization, l-diversity, multi dimensional generalization, improved symmetric and asymmetric k-anonymization, Apache Storm, MPSEC dataset
Data exposure and privacy violations may happen when data is exchanged between organizations. Data anonymization gives promising results for limiting such dangers. In order to maintain privacy, different methods of k-anonymization and l-diversity have been widely used. But for larger datasets, the results are not very promising. The main problem with existing anonymization algorithms is high information loss and high running time. To overcome this problem, this paper proposes new models, namely Improved k-Anonymization (IKA) and Improved l-Diversity (ILD). IKA model takes large k-value using a symmetric as well as an asymmetric anonymizing algorithm. Then IKA is further categorized into Improved Symmetric k-Anonymization (ISKA) and Improved Asymmetric k-Anonymization (IAKA). After anonymizing data using IKA, ILD model is used to increase privacy. ILD will make the data more diverse and thereby increasing privacy. This paper presents the implementation of the proposed IKA and ILD model using real-time big candidate election dataset, which is acquired from the Madhya Pradesh State Election Commission, India (MPSEC) along with Apache Storm. This paper also compares the proposed model with existing algorithms, i.e. Fast clustering-based Anonymization for Data Streams (FADS), Fast Anonymization for Data Stream (FAST), Map Reduce Anonymization (MRA) and Scalable k-Anonymization (SKA). The experimental results show that the proposed models IKA and ILD have remarkable improvement of information loss and significantly enhanced the performance in terms of running time over the existing approaches along with maintaining the privacy-utility trade-off.
reference: Vol. 39, 2020, No. 3, pp. 537–567