Abilities of Contrastive Soft Prompting for Open Domain Rhetorical Question Detection
keywords: Soft prompts, prompt-tuning, rhetorical questions, contrastive learning, triplet loss, pre-trained language models
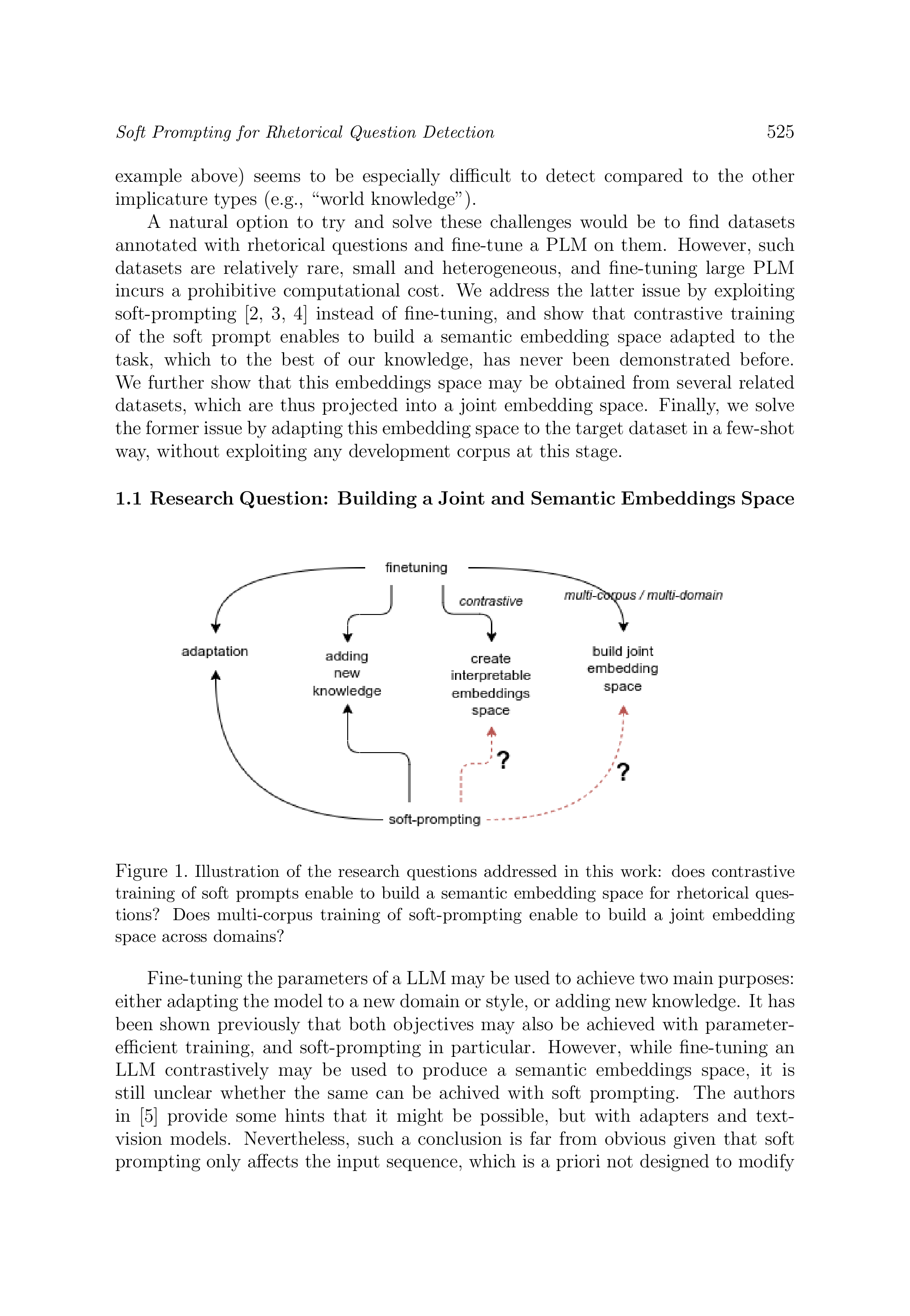
In this work, we start by demonstrating experimentally that rhetorical question detection is still a challenging task, even for the state-of-the-art Large Language Models (LLMs). We propose an approach that boosts the performances of such LLMs by training a soft prompt in a way that enables building a joint embedding space from multiple loosely related corpora. The advantages of using a soft-prompt compared to fine-tuning is to limit the training costs and combat overfitting and forgetting. Soft prompting is often viewed as a way to guide the model towards a specific known task, or to introduce new knowledge into the model through in-context learning. We show that soft prompting may also be used to modify the geometry of the embedding space, so that the distance between embeddings becomes semantically relevant for a target task, similarly to what is commonly achieved with contrastive fine-tuning. We exploit this property to combat data scarcity for the task of rhetorical question detection by merging several datasets into a joint semantic embedding space. On the standard Switchboard dataset we demonstrate that the resulting BERT-based model nearly divides by 2 the number of errors as compared to Flan-T5-XXL with only 5 few-shot labeled samples, thanks to this joint embedding space. We have chosen in our experiments a BERT model because it has already been shown with S-BERT that contrastive fine-tuning of BERT leads to semantically meaningful representations. Therefore, we also show that this property of BERT nicely transfers to the soft-prompting paradigm. Finally, we qualitatively analyze the resulting embedding space and propose a few heuristic criteria to select appropriate related tasks for inclusion into the pool of training datasets.
reference: Vol. 44, 2025, No. 3, pp. 523–548