MIDWRSeg: Acquiring Adaptive Multi-Scale Contextual Information for Road-Scene Semantic Segmentation
keywords: Deep convolutional network, attention mechanism, semantic segmentation, autonomous driving
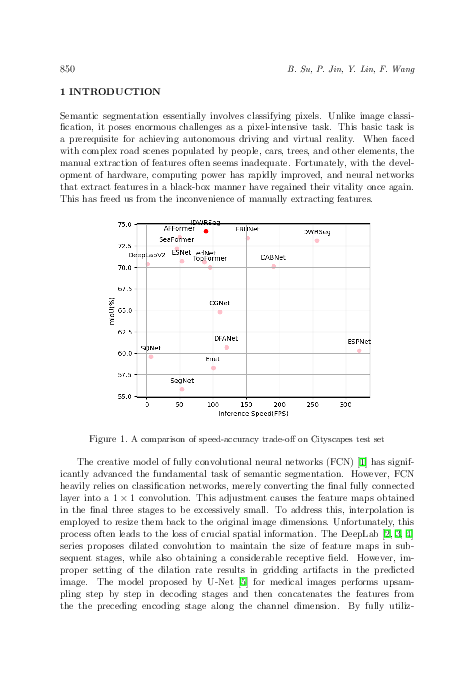
We present MIDWRSeg, a simple semantic segmentation model based on neural network architecture. For complex road scenes, a large receptive field gathered at multiple scales is crucial for semantic segmentation tasks. Currently, there is an urgent need for the CNN architecture to establish long-range dependencies (large receptive fields) akin to the unique attention mechanism employed by the Transformer architecture. However, the high complexity of the attention mechanism formed by the matrix operations of Query, Key and Value cannot be borne by real-time semantic segmentation models. Therefore, a Multi-Scale Convolutional Attention (MSCA) block is constructed using inexpensive convolution operations to form long distance dependencies. In this method, the model adopts a Simple Inverted Residual (SIR) block for feature extraction in the initial encoding stage. After downsampling, the feature maps with reduced resolution undergo a sequence of stacked MSCA blocks, resulting in the formation of multi-scale long-range dependencies. Finally, in order to further enrich the size of the adaptive receptive field, an Internal Depth Wise Residual (IDWR) block is introduced. In the decoding stage, a simple decoder similar to FCN is used to alleviate computational consumption. Our method has formed a competitive advantage with existing real-time semantic segmentation models for encoder-decoder on Cityscapes and CamVid datasets. Our MIDWRSeg achieves 74.2 % mIoU at a speed of 88.9 FPS at Cityscapes test and achieves 76.8 % mIoU at a speed of 95.2 FPS at CamVid test.
reference: Vol. 43, 2024, No. 4, pp. 849–873